F-tests and t-tests are decent for simple models. We know that \(R^2\) holds significance for simple linear regression, and that \(R_a^2\) holds significance for multiple linear regression. We can use these tests and metrics to compare different features in models across datasets. But, how do we use this for more complicated models? What about the case for a model with many predictors? If we were test different models manually for a dataset with 100 features, that’s \(2^{100}\) combinations!
Methods
Hypothesis Testings Based Methods
backwards elimination:
start with the full model, successively remove the predictor with the largest p-value greater than a selected threshold until either all p-values are below the selected threshold, or until a minimum number of features threshold is met
forward selection:
start with all possible simple (single feature) linear models, select the best model (i.e. lowest p-value), test all remaining features, select the best model for two features, and then successively repeat until either nothing else adds to the model, or until a maximum number of features threshold is met
stepwise regression (bi-directional):
essentially uses forwards and backwards elimination simultaneously, i.e. at each stage allow for any variable to be added or removed
Criteria Based Methods:
AIC (Akaike Information Criteria)
BIC (Bayes Information Criteria)
MSPE (mean-squared prediction error)
\(R^2_a\) (Adjusted R-Squared)
We actually normally use the criteria based methods (metrics) to help determine the “best” model, as we’ll show later on in this page.
AIC
\[AIC = 2(p+1) - 2\log(\frac{SSE}{n})\]
\(AIC\) estimates the relative amount of information that is lost by a given model in effort to minimize the information that’s lost.
The first term is an estimate of complexity with respect to the model, while the second term is an estimate of model fit. Normally thought of as a decent metric for prediction goals, though this is not a “hard and fast” rule.
BIC
\[BIC = (p+1)log(n) - 2logL(\hat{\beta})\]
\(BIC\) is similar estimate to \(AIC\) with slightly different parameters, where
\(logL(\hat{\beta})\) is the log likelihood function
BIC is normally thought of as a decent metric for explanation goals, though this is not a “hard and fast” rule. For a very large amount of features, the penalty term for BIC is larger than AIC.
The first term is constant with respect to \(g\), and it can be shown the second term can be estimated to \(-log(L(\hat{\beta})) + (p+1) + c\) (i.e. model complexity + model fit)
\(\rightarrow AIC(g(x; \hat{\beta}))\)
\(\rightarrow BIC(g(x; \hat{\beta}))\)
Procedure for Using the Methods
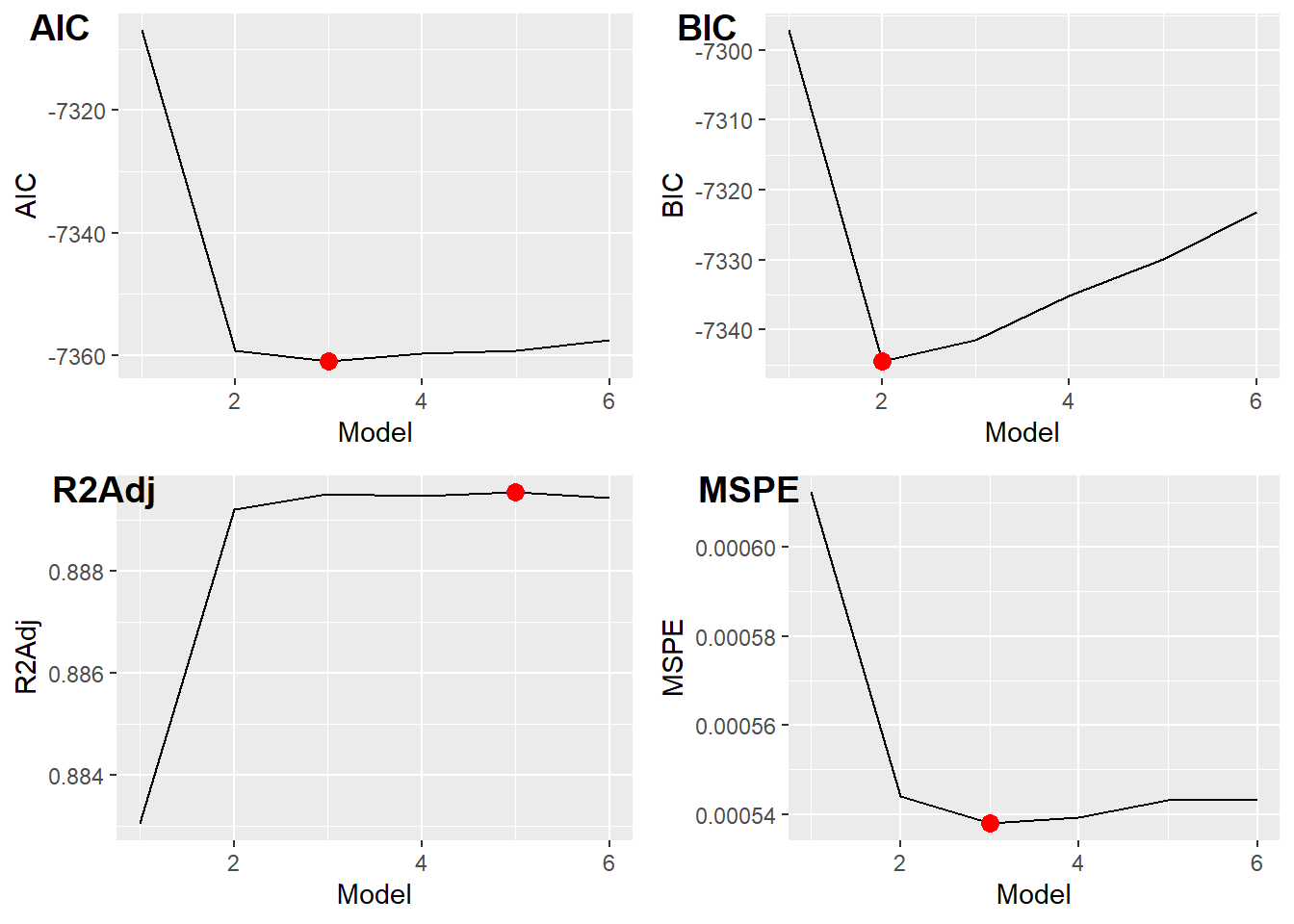
MSPE requires testing and training split datasets, while it is just a recommendation for AIC, BIC, and \(R^2_a\)
Split data into training/test sets
Fit several competing models (training set)
Can use backwards, forwards, or bi-directional algorithms to help pick the models to test (more on this later)
Calculate metric(s)
Choose the optimal model
Minimize \(AIC\)
Minimize \(BIC\)
Minimize \(MSPE\)
Maximize \(R^2_a\)
Post-hoc Consideration: Multicollinearity
Recall the issue with multicollinearity, which is when there is linear dependence between columns of data. This is a concern because lienar dependence causes non-invertibility in the matrices \(X^TX\) and \(XX^T\) for any given matrix \(X\). This is disruptive in creating MLR models.
We can test for multicollinearity through correlation matrices, or Variance Inflation Factors (VIF). In particular, VIF for the \(j^{th}\) predictor is \(VIF_j = \frac{1}{1 - R^2_j}\). This is \(R^2\) value associated with regressing the \(j^{th}\) predictor on the remaining predictors. Anything over a VIF of 5 is generally considered indicative of multicollinearity.
Rows: 1232 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (7): OBP, SLG, BA, WP, RD, Playoffs, Champion
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
We can systematically implement functions for forwards and backwards selection using update(), but one method that can be directly implemented in R is through regsubsets().
Update
Create SLR, Update To Add Variable, Update to Remove Variable
Code
# create model to predict WP from OBPmod<-lm(data=df, WP~OBP)summary(mod)
Call:
lm(formula = WP ~ OBP, data = df)
Residuals:
Min 1Q Median 3Q Max
-0.232282 -0.044727 0.001874 0.044186 0.185660
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.24102 0.03837 -6.282 4.64e-10 ***
OBP 2.26964 0.11745 19.324 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.06187 on 1230 degrees of freedom
Multiple R-squared: 0.2329, Adjusted R-squared: 0.2323
F-statistic: 373.4 on 1 and 1230 DF, p-value: < 2.2e-16
Code
# update model to add SLGmod<-update(mod, .~.+SLG)summary(mod)
Call:
lm(formula = WP ~ OBP + SLG, data = df)
Residuals:
Min 1Q Median 3Q Max
-0.229835 -0.044301 0.001687 0.044303 0.181604
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.22136 0.04123 -5.369 9.46e-08 ***
OBP 2.07235 0.19188 10.800 < 2e-16 ***
SLG 0.11257 0.08659 1.300 0.194
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.06185 on 1229 degrees of freedom
Multiple R-squared: 0.2339, Adjusted R-squared: 0.2327
F-statistic: 187.7 on 2 and 1229 DF, p-value: < 2.2e-16
Code
# update model to remove OBPmod<-update(mod, .~.-OBP)summary(mod)
Call:
lm(formula = WP ~ SLG, data = df)
Residuals:
Min 1Q Median 3Q Max
-0.220219 -0.045113 0.002577 0.046060 0.175795
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.16101 0.02210 7.286 5.71e-13 ***
SLG 0.85224 0.05542 15.377 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.06469 on 1230 degrees of freedom
Multiple R-squared: 0.1612, Adjusted R-squared: 0.1606
F-statistic: 236.4 on 1 and 1230 DF, p-value: < 2.2e-16
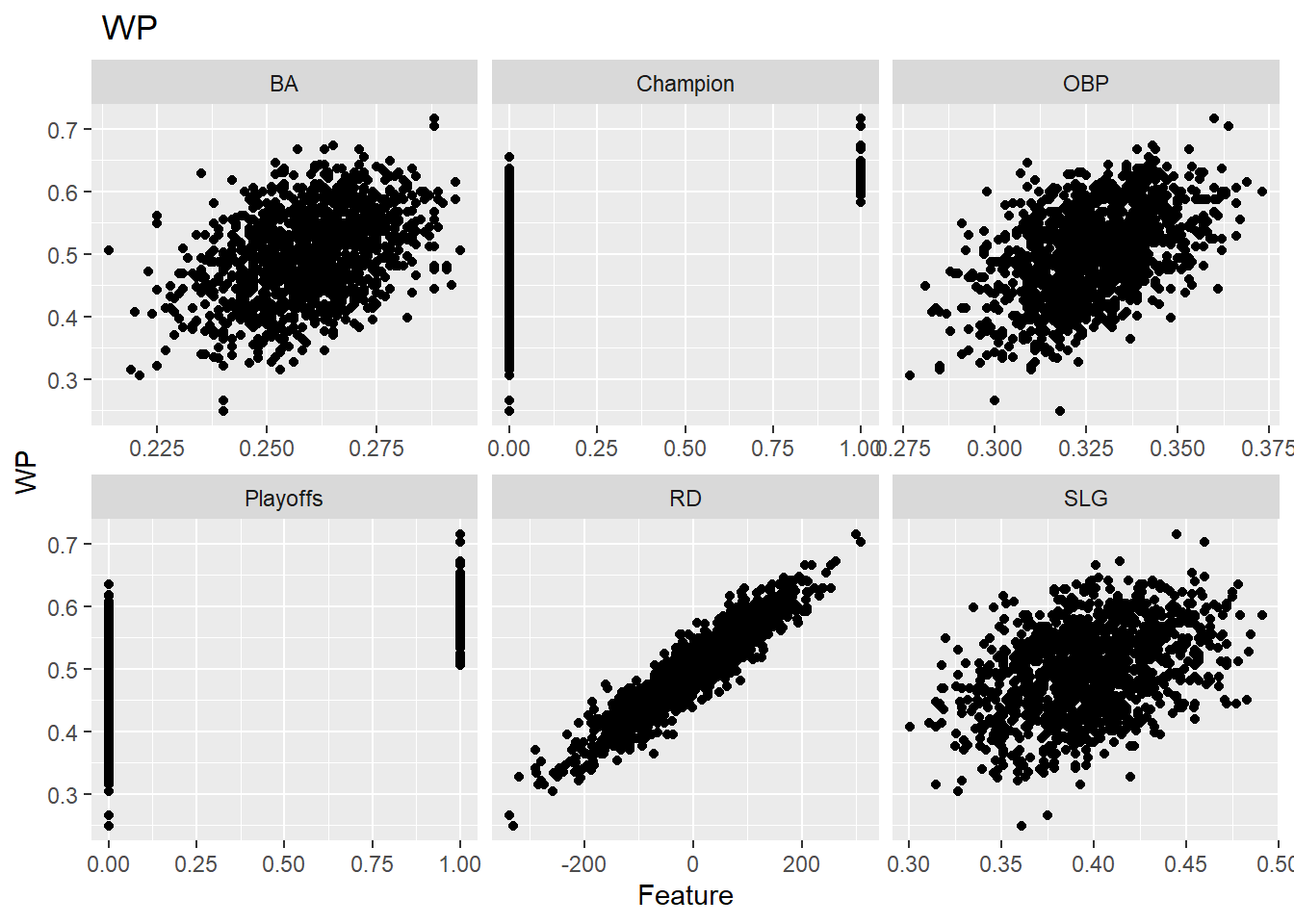
Each row represents a progressive combination of features, representing the best model of different sizes, with each row adding a new feature. The best models are determined by lowest SSE, or sum squared error.
Custom Function
Custom Function for MSPE
Code
# function for returning mspe form a regsubset outputmspe_loop<-function(train_set, test_set, regsubset_summary, response){# observed values from test setobs<-test_set[[response]]# initialize mspe tracking listmspe_results<-c()loop_size<-dim(regsubset_summary$which)[1]for(modelin1:loop_size){# create modeltrue_cols<-names(which(regsubset_summary$which[model,]))# remove intercept featuretrue_cols<-true_cols[true_cols!='(Intercept)']formula<-paste(unlist(true_cols), collapse ='+')formula<-paste('~', formula, '')formula<-paste(response, formula, '')lmod<-lm(data =train_set, as.formula(formula))# calculate MSPEpreds<-lmod%>%predict(test_set)mspe<-mean((obs-preds)^2)mspe_results<-c(mspe_results, mspe)}return(mspe_results)}
Custom Function for Creating a Long Dataframe
Code
# function for making dataframe long with respect to response variablecreate_long_df<-function(df, response){df_long<-pivot_longer(df, cols =names(df%>%select(-all_of(response))), names_to ='feature_names', values_to ='feature_values')return(df_long)}
Custom Function for Plotting Facets from a Long Dataframe
Code
# create function for faceted plotsplot_long_facets<-function(df_long, subset_type, response){title_text<-paste(subset_type, response)ggplot(df_long, aes(x=feature_values, y=!!sym(response)))+geom_point()+facet_wrap(~feature_names, scales ='free_x')+ggtitle(title_text)+xlab('Feature')}
Create test/train set and Run Custom Model Plotting
Code
set.seed(42)n=floor(0.8*nrow(df))#find the number corresponding to 80% of the dataindex=sample(seq_len(nrow(df)), size =n)#randomly sample indicies to be included in the training set# playoffstrain=df[index, ]#set the training set to be the randomly sampled rows of the dataframetest=df[-index, ]#set the testing set to be the remaining rows