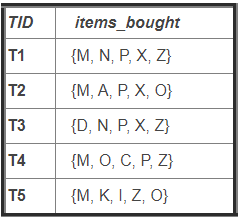
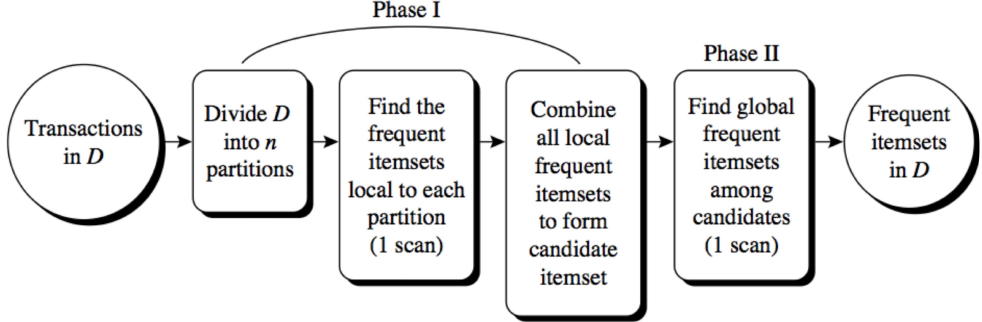
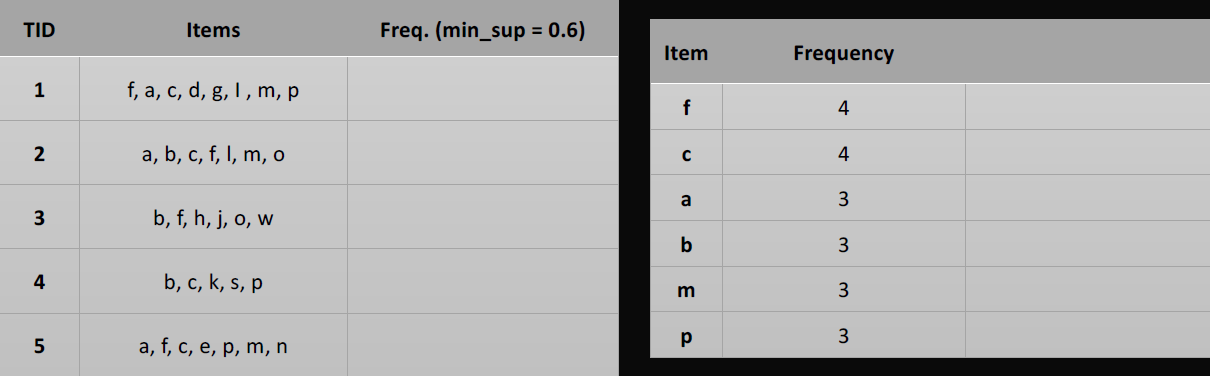
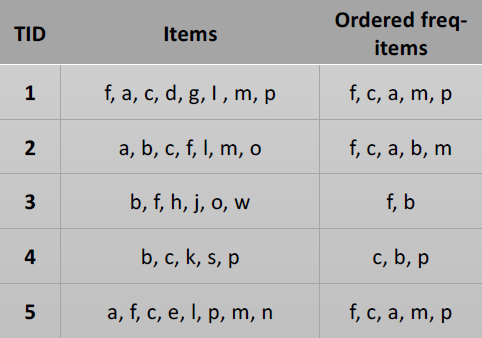
Two prime examples of this are items purchased in transactions and movies watched in a library.
The Basics
Support
Support quantifies how often an itemset appears in a dataset (proportion).
Let \(I\) be an itemset, then:
\(Support(I) = \frac{\text{number of sets containing } I}{\text{total number of sets}}\)
Suppose we have 100 customer’s movie watchlists, and we’re interested in making association rules surrounding movie \(M\).
We know that movie (or movie set) \(M\) is in 10 of the watchlists.
\(Support(M) = \frac{10}{100}\)
Additionally, we could have support for an association rule (\(Support(A \rightarrow C)\)), where \(A\) is the antecendent and \(C\) is the consequent (both are itemsets), which would look like:
\(Support(A \rightarrow C) = \frac{\text{number of sets containing } A \text{ and } C}{\text{total number of sets}}\)
Confidence
Confidence quantifies the likelihood an itemset’s consequent occurs given its antecent (i.e. the probability a consequent occurs given its antecent).
Let \(A\) be an itemset’s antecent and \(C\) be an itemset’s consequent, then:
\(Confidence(A \rightarrow C) = \frac{\text{proportion of sets containing} A \text{ and } C }{\text{proportion of sets containing} A}\)
Note that the concept of confidence is roughly derived with the help of the concept of conditional probability.
\(Confidence(A \rightarrow C) = P(C|A) = \frac{P(C, A)}{P(A)}\)
A key difference is that the numerator is is not a true intersection of events, but it contains the every element in itemsets \(A\) and \(C\). It’s more clear to use the respective definitions of support here.
\(Confidence(A \rightarrow C) = \frac{Support(A \cup C)}{Support(A)}\)
Suppose we want to recommend a movie (or movie set), \(M_2\), and we’re creating rules based on those who have watched the movie (or movie set) \(M_2\).
\(Confidence(M_1 \rightarrow M_2) = \frac{\text{proportion of watchlists containing} M_1 \text{ and } M_2} {\text{proportion of watchlists containing} M_1}\)
\(= \frac{Support(M_1 \cup M_2)}{Support(M_1)}\)
Lift
Lift assesses the performance of an association rule by quantifying an improvement (or degradation) from the initial prediction, where the initial prediction would be the support of the antecent.
\(Lift(C \rightarrow A) = \frac{Confidence(A \rightarrow C)}{Support(C)}\)
\(= \frac{\frac{Support(A \cup C)}{Support(A)}}{Support(C)}\)
\(= \frac{Support(A \cup C)}{Support(A)Support(C)}\)
Suppose we have a rule suggesting we recommend a movie (or movie set), \(M_2\), to those have seen movie(s) \(M_1\) (i.e. \(M_1 \rightarrow M_2\)).
We gather the following measurements:
- \(Support(M_1) = P(M_1) = 0.4\)
- \(Support(M_2) = P(M_2) = 0.1\)
- \(Confidence(M_1 \rightarrow M_2) = \frac{Support(M_1 \cup M_2)}{Support(M_1)} = 0.175\)
- \(Lift(M_1 \rightarrow M_2) = \frac{Confidence(M_1 \rightarrow M_2)}{Support(M_2)} = 1.75\)
How to Interpret Lift
Because \(lift((M_1 \rightarrow M_2)) > 1\), this rule provides evidence that the suggesting \(M_2\) to those who have have seen \(M_1\) is better than just suggesting \(M_2\).
In general, this yields the result that if \(lift > 1\), the association rule improves our initial prediction.
Maximal Itemset
Maximal Itemset: itemset in which none of its supersets are frequent.
Closed Itemset
Closed Itemset: itemset in which none of its immediate supersets have the same support count as the itemset, itself.
k-itemset
k-itemset: itemset which contains k items.
When finding frequencies, can refer to each sized frequency set as n-frequent, where n is the number of items in an itemset (or subset).
Apriori Property
Apriori Property: all non-empty subsets of frequent itemsets must be frequent.
Given a frequent itemset, all non-empty subsets of the frequent itemset are frequent as well.
Antimonotonicity
Antimonotonicity: If a set cannot pass a test, all its supersets will fail the test as well.
Roughly the contrapositive of the Apriori Property for association rules.
If an itemset is infrequent, all its supersets will be infrequent as well.
Maximum Number of of Possible Frequent itemsets (excluding the emptyset)
\(2^n - 1\), where \(n\) is the total number of items in the dataset. This is actually problematic due to the factorial growth per element.
For example, take a frequent itemset with just 100 elements. The total number of frequent itemsets that it contains is:
\(\sum\limits_{n = 1}^{1000}{100 \choose n} = 2^{100} - 1 \approx 1.27 x 10^{30}\)